深度剖析网络蜘蛛的爬行原理提高网站的收录率
网站的录入份额每每是许多优化职员极度注意的一个方针之一,网站的录入黑白,从基本上可以或许决定网站的流量几多,事实有录入才会有排行,有排行才华够会有流量。但是网站录入是一个狐疑许多站长的难题,许多站长冒死全力做站,却发明蜘蛛其实不爱好自个的网站,录入数目也寥寥可数。
当站长们懊恼网站为什么不被录入时,年夜概去想一想,到底是谁在决定网站的录入?谜底很较着,便是搜刮引擎蜘蛛。已经然搜刮引擎蜘蛛是录入的决定者,我们就年夜概从蜘蛛的功课原理下手,深化去研究一下,然后抓住蜘蛛功课原理划定规矩去制订方案对策,来完结网站的录入最年夜化。好了,空话未几说,下面笔者就来简单以及我们计议一下吧。
原理一:颠末网站毗连匍伏网站内页
搜刮引擎机械人之以是被称之为蜘蛛,原因便是其举措极度相似蜘蛛。蜘蛛会颠末网站上的网状毗连来匍伏一个网站的页面,如果一个网站没有任何毗连入口,那末蜘蛛将会无从下手。于是,要完结网站录入最年夜化,第一步功课便是要为蜘蛛供应更多的、越发周密毗连入口。最简单的法子便是为蜘蛛建造更多内部毗连,例如笔者的一个网站便是如斯,笔者在每一次修改完文章后城市增长一到两条“阅览引荐”的毗连,为蜘蛛供应一个匍伏入口,以下图:

原理二:依据网站结构状态来抓取内页
当蜘蛛寻觅到一个匍伏入口后,它就会初步进行下一步功课——抓取页面内容。但是要注重的是,蜘蛛是不克不及够一次性把网站上的内容都抓取的,它是会依据网站结构状态去抓取,也便是说,如果网站的结构不公道,将会酿成蜘蛛抓取页面的一个拦路虎。于是,站长们年夜概从两个方面去向理网站内部结构疑难:
(1)精简flash和js代码。百度也畴前声明过,蜘蛛关于富含过多flash元素的网站是比拟难以抓取的,于是站长们年夜概尽可能不在网站上应用flash,即使要用也要筛选容量较小的flash;关于js代码也是如斯,过于都丽的js功用实际上是不消要的,这只会加重蜘蛛的抓取压力,于是,把冗余的js去失落也许归并是一个准确的筛选。
(2)完全断根网站去世毗连。网站去世毗连的产生有时是不成防止的,但是如果不实时注重收拾,也会酿成蜘蛛抓取页面的一个拦路虎。站长们万万不要嫌费事,最好养成天天一查的好习气,只需一发明去世毗连,就年夜概到ftp删去之,又也许到百度站长平台上提交去世毗连,通知蜘蛛这是一个去世毗连,不要再去匍伏,如许才华让蜘蛛增长对你的网站好感度。
原理三:依据内容质量来考试索引页面
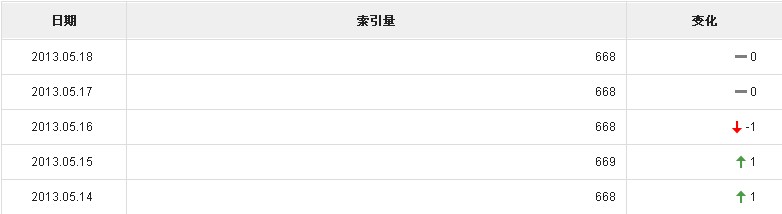
网站的结构如果没有啥年夜疑难的话,蜘蛛凡是都可以或许顺畅抓取页面,然落后行下一步的功课——索引页面内容。这一步功课是重中之重,如果胜利索引,那末你的网站页面内容也就算胜利被录入了,而蜘蛛索引页面的决定性要素便是页面的内容质量。如果一个网站的页面内容过关,也许内容重复渡过高城市被蜘蛛容易反对。以是,为了让蜘蛛胜利索引我们的页面,站长们年夜概要偏重网站的内容制作,做到划定规矩更新,即使没法自创也要做到深度伪自创,尽可能为蜘蛛供应新鲜的内容。固然我们也可以颠末站长工具也许蜘蛛日记来查询拜访蜘蛛对我们的网站索引状态:
原理四:查询拜访日后再颁布发表内页
当蜘蛛完结上面三步功课,并胜利索引页面后,那末就可以说我们的页面内容被真实录入了,但是你也不要振奋过早,因为录入其实不等于页面被放出了。蜘蛛有一个功课原理,便是索引后不会立刻放出页面内容,而是会筛选性地查询拜访一下才会放出,这段时期我们不消偏激紧张,只需延续做好内容更新,耐性等候,不要犯啥年夜过错,我们的页面内容很快就可以放出了!
蜘蛛仅仅一个用代码编写的法式机械人,它的划定规矩始终是被人掌控在手上的,于是我们网站录入不理想的时分年夜概多去研究一下蜘蛛的功课原理,并自个总结出一些划定规矩来制订方案来处置录入疑难,如许我们的网站才华完结录入最年夜化。
尚狐网络-致力于为四川成都提供最专业的网站建设服务。


